
1. 需求背景
通过介绍locust分布式负载测试工具的使用方法,让大家能快速掌握性能测试的基本方法,提高工作效率。
2. 术语解释
性能测试定义:指通过自动化测试工具模拟多种正常,峰值以及负载条件对系统的各项性能指标进行测试
响应时间:测单接口的性能,响应时间可以简单理解为用户发送一个请求到服务器返回的响应数据这段时间就是响应时间。
并发用户数:某一物理时刻同时向系统提交请求的用户数,提交的请求可能是同一个场景,也可以是不同场景。
TPS: 全拼是Transaction per second,每秒事务数;测单接口的性能,一个事务可以理解为一个客户机向服务器发送请求然后服务器做出反应的过程。
单推: 下发一条消息只推送一个用户id (多个用户收到消息是通过推送多条消息来实现的)
多推:一条推送消息可以同时推送多个用户id。(多个用户收到消息是通过一条消息来实现的)
3. 测试策略
3.1 需求分析:
针对需求,现需测试下列几个场景:
使用域名单推,查看发送的最大TPS
使用域名多推,查看发送的最大TPS
3.2 测试方法
(1)性能测试的前期准备:
分析业务场景:场景内容有哪些,范围较广,可与开发、产品,讨论确定本次测试的范围
分析测试策略:得到设计的测试场景有哪些
分析生产环境: 分析用户实际使用场景及系统详细部署情况
选择测试工具:用什么方式来测试性能
(2)性能测试的目的:
性能测试则通过提前模拟场景压力,发现系统中可能的瓶颈,进行系统调优,减少服务器宕机的风险。
性能测试还可以用来评估待测软件在不同负载下的系统负载能力,为系统部署,提供性能数据决策
(3) 性能下降曲线分析法:
性能随用户数增长而出现下降趋势的曲线,如图所示:

蓝线表示 TPS,黄色表示响应时间
在 TPS 增加的过程中,响应时间一开始会处在较低的状态,也就是在 A 点之前。接着响应时间开始有些增加,直到业务可以承受的时间点 B,这时 TPS 仍然有增长的空间。再接着增加压力,达到 C 点时,达到最大 TPS。我们再接着增加压力,响应时间接着增加,但 TPS 会有下降。
3.3 测试工具
使用分布式压测工具locust
3.4 测试环境
3.4.1 压测数据流程图
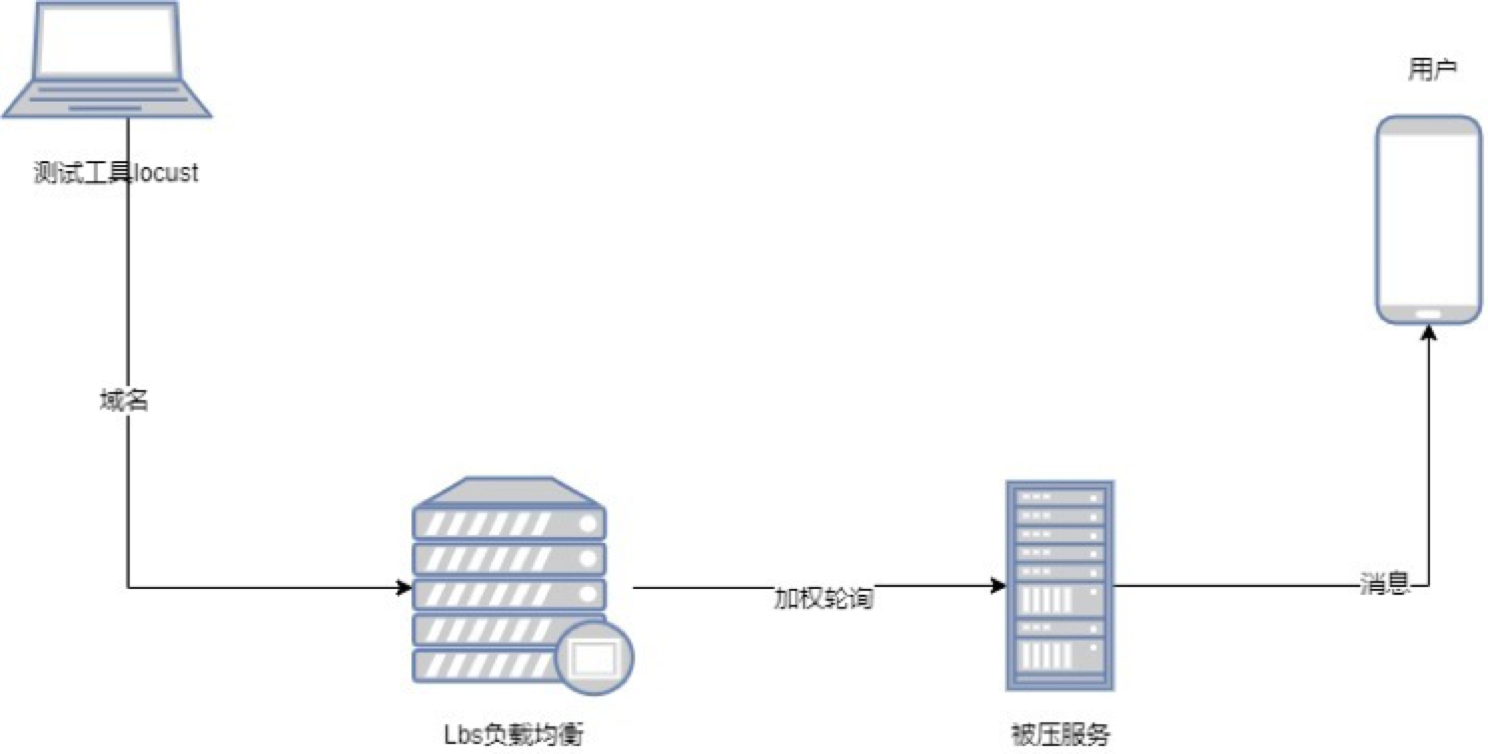
3.4.2 被测系统
API服务为双机双节点部署方式,相关依赖服务部署也都部署在这台服务起上,且都是双节点
服务器资源:4核16G
使用域名压测:域名通过lbs转发到服务器
4 .测试工具Locust
4.1 简要
JMeter和LoadRunner性能测试工具,是比较老牌的,都是通过线程来作为虚拟虚拟用户,而Locust是基于协程实现并发用户的,协程是比线程更小的单位,也称为子线程,在一个线程中可以运行多个协程。所以基于协程的Locust,在进行分布式部署时,不仅可以进行多机压测部署,而且还可以在一台宿主机中完成
4.2 压测工具:locust,版本:0.14.5
4.3 Locust本地宿主机部署步骤
(1)首先我们需要通过python+locust写出程序需要运行的ABC.py文件

脚本说明:
新建一个类TPush(TaskSet),继承TaskSet,该类下面写需要请求的接口以及相关信息; self.client调用get和post方法,和requests一样;
@task装饰该方法表示为用户行为,括号里面参数表示该行为的执行权重:数值越大,执行频率越高,不设置默认是1;
on_start方法:当模拟用户开始执行该 TaskSet 类时,将调用该方法;
WebsiteUser()类用于设置生成负载的基本属性:
l tasks:指向定义了用户行为的类;
l min_wait:模拟负载的任务之间执行时的最小等待时间,单位为毫秒;
l max_wait:模拟负载的任务之间执行时的最大等待时间,单位为毫秒。
(2)创建locust运行的master:
写好需要运行的locust文件之后,我们需要先利用命令“locust -f xxxx.py --master”创建一个master,这个master不参与创建并发用户的工作,它主要是进行监听以及收集统计数据.
2.1 提供给web端,我们完全可以利用python当中的os的system函数直接编写出cmd命令进行运行

2.2 使用no-web,也可以利用python当中的os的system函数直接编写出cmd命令进行运行

当然也可以直接输入命令执行

此时我们运行py文件,可以看到以下的信息,则说明我们已经启动了locust分布式的主节点master

(3)创建locust运行的slave
我们就可以创建用于制造并发用户的分支节点slave了,方法就是复制master的文件,然后修改一下文件名称,一定要保证slave运行的文件与master文件是一样的,自己的机器有多少个cpu就可以弄多少个slave,一般一个slave会使用一个cpu创建并发用户
ABC.py ABC_slave1.py 3.1 然后每个slave文件中需要在主函数中输入cmd命令

3.2 也可直接输入命令执行slave

运行多个slave,可以查看以下内容来判断分布式是否部署成功

当开启全部slave后,可以查看master的控制台信息,看到下面的信息则表示locust分布式部署成功了

(4)、打开web端同样也可以查看到分布式的slave
登陆页面

启动压测前,需要填写用户总数(Number of total users to simulate)、每秒增加的用户数(Spawn rate)以及域名(HOST)。
每秒增加的用户数(Spawn rate)会在用户数达到用户总数(Number of total users to simulate)时停止增加。

查看slave节点数
由上图可以看出slave都存于running状态,且压力分布均匀。
测试结果数据下载

在locust当中使用web模式进行压测时是没有办法设定执行时间的,所以web模式下的压测会一直运行,直到点击stop才能运行,如果想在web模式下运行压测一段时间自动停止的话,那么需要在参数配置时加入stop_timeout参数即可,value值是执行的时间(单位是s)
class websitUser(HttpLocust):
task_set = Login #定义需要执行的任务集
min_wait = 1000 #最小等待时间
max_wait = 2000 #最大等待时间
stop_timeout = 60 # 停止的时间
5.通过locust可视化界面判断接口性能瓶颈
在总用户数为100,每秒增加1个用户的情况下运行一段时间,我们查看locustweb界面:

发现tps稳定停留在某个数值(9.8),这时候我们点击Charts查看TPS、延迟和用户数的详情分布图
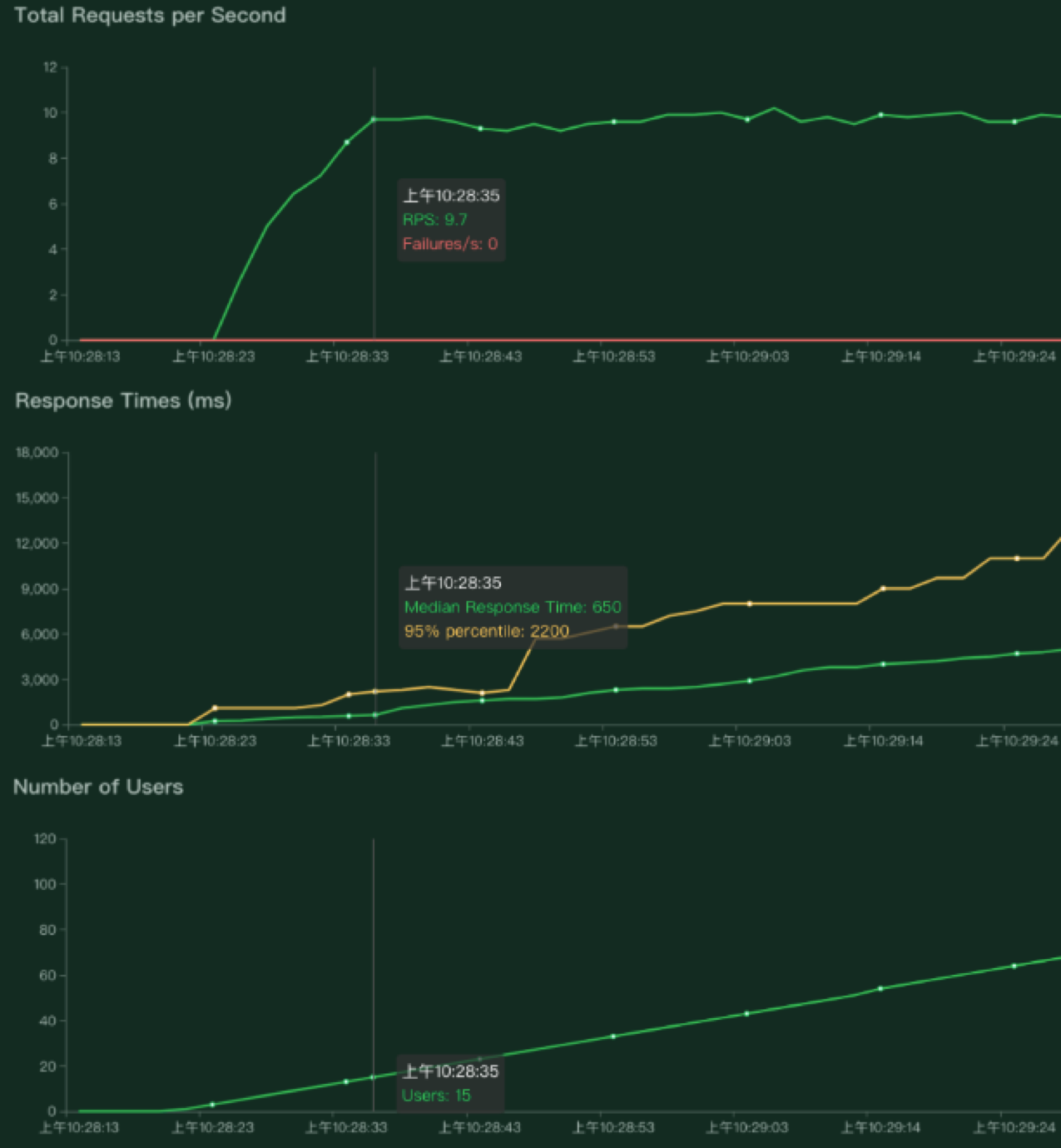
可以看出在TPS在10之前,随着用户数的增加而增加;但增加到10之后,用户数再怎么增加tps依然稳定在10左右,只有延迟在增加;
在查看服务器性能
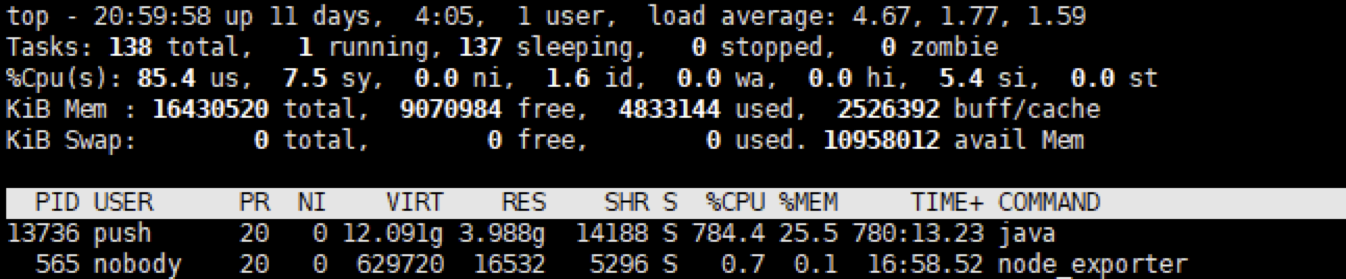
可以看出cpu都被该程序占用,那么我们可以初步认为该接口的tps为10,且瓶颈在cpu上。
6.数据采集实操
单推接口:/single

多推接口:/mutiplie
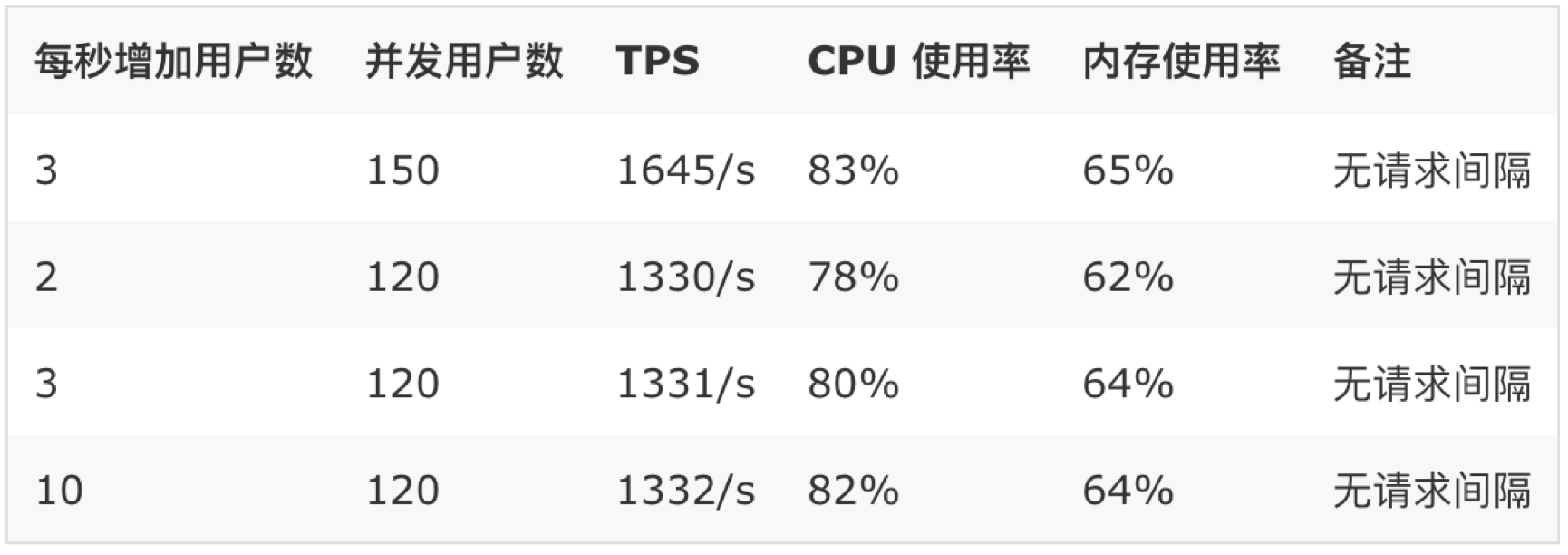
7. 数据分析
压测时内存消耗没有cpu消耗明显。从系统稳定性考虑,需要考虑服务不挂,稳定情况下的性能指标。需要对数据采集进行分析,分析得如下结论:
单推:每秒增加用户数为3,并发用户数为160,cpu消耗在80%左右来持续压测得出下面的性能各项指标。
多推:每秒增加用户数为2,并发用户数为120,cpu消耗在78%左右来持续压测得出下面的性能各项指标。
注:(多推时,考虑到body的大小,deviceTokens设置3个数,对接口来说无差异,在数据落地时才消耗资源,另外借助单推的经验和多推的系统逻辑,简单可以定位出多推的资源消耗。所以数据采集相对少些。)
8.测试结论

单推接口: 接口TPS压测结果为 1757/s,90%请求可以在 0.1 秒内响应,因线上 部署多台机器,所以该 tps 只限当前配置和部署的情况下,主要瓶颈是设备升级;
多推接口: 接口TPS压测结果为 1342/s,90%请求可以在 0.1 秒内响应,因线上部 署多台机器,所以该 tps 只限当前配置和部署的情况下,主要瓶颈是设备升级;
文章引用的数据,仅代表特定压测环境下的服务表现







